OS-Lab3
一、进程相关函数
在做lab3的实验时,发现函数嵌套的情况很多,首先整理这一块的逻辑。
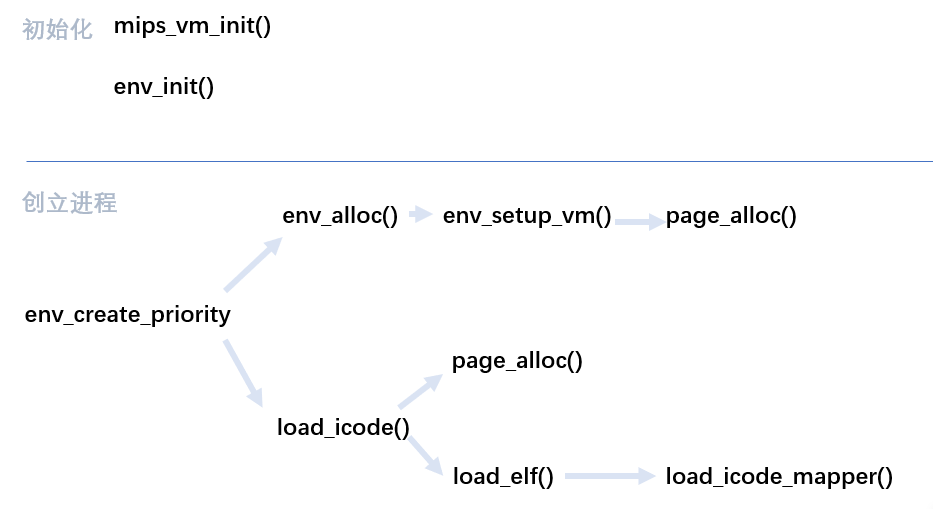
箭头表示函数调用
1.初始化:
- 申请envs[]的空间;初始化env_free_list(把空闲进程env_status设置为ENV_FREE)
2.创立进程:设置env_pri
env_alloc():
从env_free_list取出一块空闲进程;
设置env_id,env_status,env_parent_id,env_tf.cp0_status,env_tf.regs[29]
env_setup_vm():
- 为进程创建一页页目录,并建立好自映射
- 设置env_pgdir,env_cr3
load_icode():
- 为进程申请一页作为栈,并建立好映射
- 设置env_tf.pc(为load_elf返回的binary的入口)
- load_elf()/load_icode_mapper():
- 以一个段(segment)为单位,把binary(进程的内容的二进制镜像)的内容复制到所在内存的虚拟地址
- (load_elf负责找入口,mapper负责copy)
3.切换进程
- 保存当前进程的上下文,设置env_tf,env_tf.pc
- 恢复要启动的进程上下文,并启动新进程,设置env_status,env_pgdir,操作了env_tf,env_id
二、进程控制块(PCB)
进程控制块(PCB) 是系统为了管理进程设置的一个专门的数据结构,用它来记录进程的外部特征,描述进程的运动变化过程。系统利用PCB 来控制和管理进程,所以 PCB 是系统感知进程存在的唯一标志 。
首先贴出PCB的构成。
1 | |
1.env_tf
env_tf的类型是struct Trapframe,定义在trap.h中。
1 | |
①regs[29]:通用寄存器中的29号是栈寄存器,在env_alloc()的时候设置为USTACKTOP(是用户栈,内核栈在0x8040 0000)

我们回忆起在load_icode()也申请了一页作为栈映射到了USTACKTOP-BY2PG。刚好是regs[29]所在起始位置的下一页。
所以在env_alloc()的时候调整了栈指针的位置为USTACKTOP,在env_icode()时为栈专门申请了一页的空间[USTACKTOP-BY2PG,USTACKTOP]。
②pc:程序计数器,用于存放下一条指令的地址
上面的函数我们一共有两个地方用到了pc。
第一处在env_alloc()
e->env_tf.pc = entry_point;
即将进程的起始地址移动到了binary的e_entry,可执行程序入口点地址。
第二处在env_run()
curenv->env_tf.pc = curenv->env_tf.cp0_epc;
env_tf.cp0_epc存的是下一条指令的地址,则将下一个pc的地址保存了,回复这个进程的时候可以直接跳转到那个位置。
③cp0_status
在env_alloc()中进行了这样的设置:
e->env_tf.cp0_status = 0x10001004;
指导书中提到“MIPSR3000 里的SR(status register) 寄存器就是我们在env_tf里的cp0_ status,R3000 的SR 寄存器的低六位是一个二重栈的结构。”
二重栈在这个地方应该是指以大小2为单位的栈。所以实际上在中断发生和中断恢复时,会经历这样的倒腾。
KUo 和IEo 是一组,每当中断发生的时候,硬件自动会将KUp 和IEp 的数值拷贝到这里;KUp 和IEp 是一组,当中断发生的时候,硬件会把KUc 和IEc 的数值拷贝到这里。其中KU 表示是否位于内核模式下,为1 表示位于内核模式下;IE 表示中断是否开启,为1 表示开启,否则不开启2。
而每当rfe 指令调用的时候,就会进行上面操作的逆操作。—《指导书》
我后来发现PPT里有,请跳过这部分。
这一段没有关于KUo、IEo、KUp、IEp、KUc、IEc的解释,我估计是这样的,画图说明。

下面这一段代码在运行第一个进程前是一定要执行的,所以就一定会执行rfe这条指令。
2
3
4lw k0,TF_STATUS(k0) # 恢复CP0_STATUS 寄存器
mtc0 k0,CP0_STATUS
j k1
rfe
KU:1–内核态,0–用户态;IE:1–开启中断,0–关闭中断。(这里应该是看KUc,IEc)
rfe会发生类似于中断恢复的操作,往右移动。我们为了设置初始状态为000001b(进入用户态,开启中断),所以我们先设置为000100b,再触发ref指令,使之变成000001b。
我们之前的设置是e->env_tf.cp0_status = 0x10001004;其中还设置了“第28bit 设置为1,表示处于用户模式下。第12bit 设置为1,表示4 号中断可以被响应。”
2.lcontext(curenv->env_pgdir)
curenv->env_pgdir是页目录的内核虚拟地址
lontext 中有一句指令sw a0,mCONTEXT (a0是第一个参数即新进程的内核虚拟地址)
1 | |
在pmap.c中有这样一句mCONTEXT = (int)pgdir;是把全新的页目录kva存到mCONTEXT
这里就是把curenv的页目录kva存到mCONTEXT,mCONTEXT除了第一次创建页目录的使用,还会在do_refill里使用,这里暂不了解。这里大概是为了开启一个全新的进程时需要创建进程的页目录,需要mCONTEXT。
三、关键函数理解
首先第一部分我觉得比较关键的是对于一些非常关键的函数的理解与把握,这些函数是我们本次实验的精华所在,虽然好几个实验都不需要我们自己实现。首先是从第一个我们要填的函数说起吧:
1.env_init
1 | |
以上是env_init的实现。就是初始化env_free_list,然后按逆序插入envs[i]。
这里唯一值得并需要引起警惕的是逆序,因为我们使用的是LIST_INSERT_HEAD这个宏,任何一个对齐有所了解的人应该都知道,这个宏每次都会将一个结点插入,变成链表的第一个可用结点,而我们在取用的时候是使用LIST_FIRST宏来取的,所以如果这里写错了的话,可能在调度算法里就要有所更改。
可能会有同学问为什么NENV是envs的长度,这个实际上在pmap.c里面的mips_vm_init里可以找到我们的证据,证明envs数组确实给它分配了NENV个结构体的空间,所以它也就有NENV个元素了。
2.env_setup_vm
1 | |
其实这个函数并不需要我们实现,但是我还是想讲一讲这个函数的一些有意思的地方。
我们知道,每一个进程都有4G的逻辑地址可以访问,我们所熟知的系统不管是Linux还是Windows系统,都可以支持3G/1G模式或者2G/2G模式。3G/1G模式即满32位的进程地址空间中,用户态占3G,内核态占1G。这些情况在进入内核态的时候叫做陷入内核,因为即使进入了内核态,还处在同一个地址空间中,并不切换CR3寄存器。但是!还有一种模式是4G/4G模式,内核单独占有一个4G的地址空间,所有的用户进程独享自己的4G地址空间,这种模式下,在进入内核态的时候,叫做切换到内核,因为需要切换CR3寄存器,所以进入了不同的地址空间!
而我们这次实验,根据./include/mmu.h里面的布局来说,我们其实就是2G/2G模式,用户态占用2G,内核态占用2G。所以记住,我们在用户进程开启后,访问内核地址不需要切换CR3寄存器!其实这个布局模式也很好地解释了为什么我们需要把boot_pgdir里的内容拷到我们的e->env_pgdir中,在我们的实验中,对于不同的进程而言,其虚拟地址ULIM以上的地方,映射关系都是一样的!这是因为这2G虚拟地址与物理地址的对应,不是由进程管理的,是由内核管理的。
另外一点有意思的地方不知大家注意到没有,UTOP~ULIM明明是属于User的区域,却还是把内核这部分映射到了User区,而且我们看mmu.h的布局。我们仔细地来分析一下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aYxIgE0y-1653797805142)(C:\Users\夏伟\AppData\Roaming\Typora\typora-user-images\image-20220529102258920.png)]
可以看到UTOP是0x7f40 0000,既然有映射,一定就有分配映射的过程,我们使用grep指令搜索一下 UENVS,发现它在这里有pmap.c里的mips_vm_init有所迹象:
1 | |
可以发现什么呢?其实我们发现,UENVS和envs实际上都映射到了envs对应的物理地址。
其实足以看出来,内核在映射的时候已经为用户留下了一条路径,一条获取其他进程信息的路途。而且我们其实可以知道,这一部分对于进程而言应当是只能读不可以写的。开启中断后我们在进程中再访问内核就会产生异常来陷入内核了,所以应该是为了方便读一些进程信息,内核专门开辟了这4M的用户进程虚拟区。用户读这4M空间的内容是不需要产生异常的。
1 | |
3.env_alloc
1 | |
这一部分呢,是单个进程控制块要被分配资源的时候做的一些初始化的工作,其中有几个比较有意思的点很值得深究:
1 | |
第一条可能会有比较大的疑问,为什么进程的二进制码分配到UTEXT对应的地址那里去了,而且也建立好映射关系了,怎么还要加个偏移量作为pc初始值呢?
我们知道pc初始值实际上是进程开始运行的地方,而这里为什么是UTEXT+0xb0,这0xb0是什么东西?我们需要去探究一下code_a.c或者code_b.c文件了,实际上经过一定的了解,这个文件应当是一个elf文件。看其前四个字节就能看出:
1 | |
这是elf的标准头,而实际上像这样的标准头的长度是有0xb0的长度,这个实际上我们可以把code_a.c里的数组搞出来,然后变成一个elf文件,最后使用readelf来读取出地址,这样就能明白原理了。所以UTEXT+0xb0这个虚拟地址对应物理地址里面放着的,才是真正可执行代码的第一条。
再来就是这个0x10001004这个问题,这个问题很好玩。因为R3000自身的SR寄存器与mips其他版本的SR寄存器略有不同,它的最后六位记载了是一组深度为二的二重栈,不过笔者在这里还残留着一些不大不小的问题。《see mips run》中只是提到了关于这些寄存器的作用,而没有提到中断的时候这些寄存器应当是什么状态。如果有兴趣的同学可以grep一下 “CP0_STATUS” 和”cp0_status” 说不定能发现个中玄机。
4.load_icode
这个堪称是本次实验中为数不多的坑函数之一,所以我也就重点讲一下几个要点好了。
首先要解释的就是这个page_insert函数,这个函数看起来平淡无奇,但是如果层层深入,就能发现里面的一些奥妙之处。
我们首先来看page_insert:
1 | |
实际上这个函数是这样一个流程:
先判断va是否有对应的页表项,如果页表项有效。或者叫va是否已经有了映射的物理地址。如果有的话,则去判断这个物理地址是不是我们要插入的那个物理地址,如果不是,那么就把该物理地址移除掉;如果是的话,则修改权限,放到tlb里去。
关于page_inert以下两点一定要注意:
- page_insert处理将同一虚拟地址映射到同一个物理页面上不会将当前已有的物理页面移除掉,但是需要修改掉permission;
- 只要对页表有修改,都必须tlb_invalidate一下,否则后面紧接着对内存的访问很有可能出错。这就是为什么有一些同学直接使用了pgdir_walk而没有page_insert产生错误的原因。
既然提到了tlb_invalidate函数,那么我们来仔细分析一下这个函数,这个函数代码如下:
1 | |
关于为什么要使用GET_ENV_ASID宏,助教老师给的指导书里其实没有讲太清楚,tlb的ASID区域只有20位,而我们mkenvid函数调用后得到的id值是可以超出20位的,大家可以在env_init初始化的时候打印env_id的值,然后在init.c里面create 1024个进程即可看到实际上envid最大可达1ffbfe,而使用GET宏之后最大可达ffc0,而且都可以为tlb用于区分进程,所以肯定是位数越少越好啦。而且还有一个比较有意思的地方,GET宏里实际上是让env_id先 >>11 然后 <<6 达到最后效果的,这样和>>5有什么区别呢?区别就在于 如果先>>11再 <<6,后6位一定是0!(2进制位),所以我猜后六位一定是有其独特用处的,否则在这里也不会强调清零,不过我们这次实验里还没有看到特殊用处。
1 | |
这段汇编是tlb_invalidate函数的精华所在,CP0_ENTRYHI实际上就是用来给tlb倒腾数据的,不用太在意其本身的作用。
前两句是指把之前的CP0_ENTRYHI存在k1里面暂存一下。然后我们就有一条很关键的汇编指令 tlbp ,很关键。
通过查mips手册可以知道tlbp的功能如下:
之后的几个nop应该是为tlb指令设置的流水缓冲,因为tlbp执行的周期要比一般指令长。其实这条汇编的目的就是:
To find a matching entry in the TLB.所以说实际上是把va及其对应的物理地址存在tlb里了,而且tlbp应该是依托于CP0_INDEX和CP0_EnrtyHI寄存器的。那么后面的那些读CP0_INDEX实际上是对tlbp执行是否成功的一个判断而已。注意,这里的tlbp就是在内核态下进行的,所以不会产生异常。如果在用户态下修改CP0的寄存器,或者使用tlbp汇编等,那就说明是tlb缺失或page_fault了!
那么再返回我们的page_insert来看看下一句,下一句是建立一个va与pa之间的桥梁,一个页表的建立,pgdir_walk(pgdir, va, 1, &pgtable_entry),所以说我们其实在最开始load_icode的时候,实际上是建立了不止size大小的页,还需要建立一个能够映射到该页的页表!那么在最后,为页表项的内容设置权限位PTE_R。恩,那么page_insert函数就此结束了。
page_insert函数结束了,不代表我们这个load_icode结束。下一步则是bcopy。
bcopy这个函数本身不坑,坑的是用法。首先对比原文中的这句我们来粗浅地看一下bcopy:
1 | |
我个人以为这里bzero清零比较好,因为不能保证lab2哪里有问题还会影响到这里来。我倾向于一页一页地清除目标页,分配原始页,当然实验证明这样写也是没有任何问题的。那么下面来解释一下为什么这里用的是page2kva(page),而不是用与UTEXT有关的数值?
首先我们解释过了,UTEXT+0xb0是程序的入口,何谓入口?比如我们现在启动了一个进程,我们如何能从哪里开始,该怎样跑呢?这取决于我们run一个进程前的准备工作,当然这个工作在进程切换时也需要做,其中很重要的一点就是保存pc。这一点很重要,极其重要。如果是第一次run一个进程的时候,我们的pc是务必要被设置为UTEXT+0xb0的,这也是在env_alloc里面所做的工作。之后有一些我们没有关注过的汇编程序就会默默地根据我们设置的pc去找我们的程序入口,默默地执行,遇到中断默默地保存,切换。于是就这样完成了进程的运行与切换大计。
那么我们这里bcopy不能用UTEXT来copy是因为,我们这里还没开始一个进程,没有其页目录来作为基址,所以你现在copy到的地方也只是内核的UTEXT处。我们都知道在env_run时要切换页目录,切换为进程的页目录后,我们就再也找不到这部分copy的东西了(因为env_setup_vm只复制内核页目录ULIM以上的部分)。所以我们要copy到的地方一定是要内核和每个进程均可以访问的,显而易见要copy到ULIM以上的部分。即page2kva(page)这个地方。当然,你可以选择先切换到进程的页目录,然后copy,然后在结束的时候切换回内核的页目录,
再次强调一点,bcopy也好,bzero也好,在我们编写的程序中,只要是作为访问地址来使用的(什么叫作为地址来使用,就是可以取其内容的 *address),全部都使用的是虚拟地址!
如果你还有更多的探索之心的话,我们可以这么来玩一下load_icode,你看我们之前bcopy不能copy到UTEXT的理由也知道了,那何不先切换到进程的页目录,复制完了以后再切换回来呢?事实上这种做法理论上是完全正确的,但是我在我们的实验里试验过发现不对!后来发现即使切换了页目录,也可以照常访问内核区的地址,完全没有问题!为什么?后来我才猛然想到,我们这次实验的lcontext切换页目录,完全是为tlb中断和page_fault服务的,所以指望lcontext来自动帮我们找到物理地址并且往里添加内容的话,是不可以的。
最后呢,实际上就是建个进程里的用户栈而已,这里区别开用户栈 和内存栈的区别。
多个进程运行时,实际上在内存中有一个栈型结构来存放进程的代码,数据,常量等,而在用户栈里放的则是运行过程中所定义的变量等,这点需要正确把握。当然最后要设置权限,PTE_R,这是写的权限,要设置给用户栈,否则后面进程没有办法写自己的栈了 。
5.env_create
1 | |
实际上这里env_create就很简单了,就是alloc一个进程控制块,然后加载其代码。
6.env_run
1 | |
刚刚说到的load_icode是为数不多的坑函数之一,env_run也是,而且其实按程度来讲可能更甚一筹。
那我们来一步一步分析一下这个函数的坑处。
首先是要理解进程切换,需要做些什么?实际上进程切换的时候,为了保证下一次进入这个进程的时候我们不会再“从头来过”,我们要保存一些信息,那么,需要保存什么信息呢?保存的应该是以下几方面:
[1]进程本身的状态
[2]进程周围的环境的状态,环境就是指此时的CPU的状态
那么我们可能会产生疑问,进程本身的状态怎么记录呢?
进程本身的状态无非就是进程块里面那几个东西,包括id,parent_id,pc,tf…
Trapframe里面有 cp0_badvaddr,cp0_cause,cp0_epc,regs[32]…
这些东西不是进程自己的。这些都是CPU的状态。所以说实际上一个进程控制块中的tf,就是来记录它的环境的状态的。进程本身的状态在进程切换的时候是不会变的。会变的也是需要我们保存的实际上是进程的环境信息。
谨记这一点,或许你就能开始明白run代码中的第一句:
1 | |
很多同学在这里可能遇到了他们在lab3中的最大困惑:
为什么这里不能从KERNEL_SP取东西,而是非要从TIMESTACK取。KERNEL_SP是用来干啥的?
为了搞清楚这一点,我们需要知道:什么时候我们把东西往TIMESTACK放,又是什么时候取出来的?
笔者在 ./include/stackframe.h 找到了一点端倪:
1 | |
实际上我们的TIMSTACK就是0x82000000,因为我们本次都是时钟中断,所以sp是TIMSTACK区。
而我们再仔细地观察这个头文件,发现其实里面的宏汇编 RESTORE_SOME 和env_pop_tf 几乎一模一样。TIMESTACK是时钟中断后的存储区,而KERNEL_SP应当是系统调用后的存储区。我们可以把run里面的TIMSTACK改成 KERNEL_SP试试,发现其实KERNEL_SP在第一个进程执行完之后就没更新过,这是显而易见的,因为我们第一个进程启动后,就再也没有给过内核进程控制权啊!不过我们的猜想估计要到后面的实验才能认证。
那么实际上我们在往某个寄存器比如$1里放东西的时候,应该是放到了sp为起始虚拟地址对应的物理地址处,那么就是
- env_pop_tf 负责放东西到sp(这里是TIMESTACK)中去;
- 而这开头的一段负责从sp里取出东西来(这里是TIMSTACK)。
所以我们一开始没有正在运行的进程块的时候,是不需要取的,但是一旦一个进程块运行到末尾的话,就会向TIMSTACK中存入东西。
比如我们进程1开始运行,运行到env_run的末尾,我们把当时的环境保存了下来。运行一段时间后,时钟中断导致切换,发现要到进程2了,在切换之前,我们把进程1的离开时的状态保存在其tf内,离开的状态其实就在TIMESTACK中。因为我理解的这个TIMESTACK就是当前访问CPU的寄存器所用虚拟地址,所以其所对应的值就是CPU的各个寄存器的值,所以就会在进程运行时改变,所以要更新。
注意还有一个小坑的地方在于 如果要env_pop_tf的时候,千万记得要先lcontext切换了页目录,否则是会出错的。env_pop_tf 的字面意思估计大家也明白了,就是把env里的tf 压到 寄存器里去。
四、实验难点图示
1.加载二进制镜像
这一部分的内容较多且难度较大,由三个函数共同完成,即:
- env.c中的
load_icode - kernal_elfloader.c中的
load_elf - env.c中的
load_icode_mapper
其中load_icode为实现这个功能的代码,它的功能在于:
- 分配内存
- 将二进制代码装入分配好的内存中
其中,第二步,即装入内存的操作交给了函数load_elf来完成,而load_elf的工作又被分为:
- 解析
ELF结构 - 将
ELF的内容复制到内存中
其中,第二步,即将内容复制到内存中的操作又交给了load_icode_mapper函数去进行,所以三段代码的协作方式如下图:
在函数load_elf中,我们不难发现,我们在load_icode_mapper中用到的许多参量在这里都有了很明确的实例对应,具体映射如下:
因此我们只要将给定的ELF文件进行正确解析,就能利用load_icode_mapper对其进行内容复制
函数load_icode重点在于设置PC值,即从load_elf中返回的entry_point
2.env_setup_vm函数的填写,初始化新进程地址空间
在这个函数中,内存空间被分成了如下的两个部分,即UTOP以上和UTOP以下,在UTOP以下的部分,我们需要将页目录的这一块区域清零,而在UTOP以上的部分,用户不能操作,属于内核态,因此我们可以将boot_pgdir的内容直接复制到进程的页目录中。
在UTOP之上有一块被称为UVPT的地址,这一块区域作为用户进程页目录,需要用自映射机制进行单独处理。
地址空间的结构图如下:
3.sched_yield() 进程切换的调度算法
进程的调度也是基于这个时间片来进行,主要的步骤为如下几步:
- 设置两个队列,其中一个为目前的进程调度队列
q0,另一个为一个空队列q1。 - 首先判断当前队列指针指向的队首进程的
env_status- 如果为
ENV_FREE,则要将该进程从队列中移除 - 如果为
ENV_NOT_RUNNABLE,则直接将其插入另一个队列的尾部 - 如果为
ENV_RUNNABLE,则判断这个进程的时间片是否用完,若用完则复原其时间片并将其插入到另一个队列尾部 - 当一个队列为空时,将指针转移到另一个队列队首

- 如果为